The following not significant results are hidden, use -v to show them: django_v2, 2to3, etree_generate, etree_parse, etree_process, fastpickle, fastunpickle, json_dump_v2, json_load, nbody, regex_v8, tornado_http.
defmatch(self, path): # 在解析是被调用的匹配方法,很重要但是没什么难懂的地方 match = ( self.regex.fullmatch(path) if self._is_endpoint and self.regex.pattern.endswith("$") else self.regex.search(path) ) if match: kwargs = match.groupdict() args = () if kwargs else match.groups() kwargs = {k: v for k, v in kwargs.items() if v isnotNone} return path[match.end() :], args, kwargs returnNone
def_compile(self, regex): try: return re.compile(regex) except re.error as e: raise ImproperlyConfigured(...) from e
]]>
<blockquote>
<p>原文:<a href="https://blog.europython.eu/kraken-technologies-how-we-organize-our-very-large-pythonmonolith/" target="_blank" r
记一次失败的 AI 辅助编程全历程https://wiki.blanc.site/archives/c57afff6.html2023-05-20T00:00:00.000Z2024-03-14T15:52:41.459Z前言
这表示 dark mode 下会生成 .dark 等 class。3. 在 build 过程中生成 dark mode 的样式。在 build 过程的 variants 阶段,会根据 prefers-color-scheme 的 variants 生成 .dark 等 class,并使用 dark mode 的颜色变量填充这些 class。4. 在 HTML 中使用 prefers-color-scheme media query 加载相应的样式。例如:
html <linkrel="stylesheet"href="tailwind.css"> <linkrel="stylesheet"media="prefers-color-scheme: dark"href="tailwind.dark.css">
tailwind.dark.css 是 dark mode 的样式,会在 prefers-color-scheme: dark 条件下被加载。5. 可选:使用 JavaScript 切换模式。可以使用 matchMedia 检测 prefers-color-scheme 的变化,并动态加载样式来实现模式切换。所以总体来说,Tailwind 通过定义 variants、颜色变量和生成不同模式的样式文件来实现 dark mode。hope this helps!
马后炮:回过头来看,这个回答完全没有参考价值,甚至不如前面提到 variants 的那几个回答有价值,所以说 AI 的生成式回答的随机性还是比较坑的。
然后我问了:
Tailwind CSS 如何表达 .abc .bg-white
Tailwind CSS 如何匹配父 class
Tailwind CSS 如何实现父 class 选择器
这里我是想:在当前项目中所谓的主题模式是通过控制 Layout 根 DOM 的 class name 来实现的,当 class 是 dark 时为 dark mode,是 light 时为 light mode。所以只需匹配父类就能够实现我想要的东西。事实证明这个思路确实是没问题的,但是并不是通过简单的 class 实现的。
html <divclass="light"> <pclass="light:bg-blue-500">...</p> </div>
这个 p 元素会具有 bg-blue-500 这个类,因为 light:bg-blue-500 在 .light 元素下生效了。如果没有 .light 父元素,light: 类就不会生效,和 Tailwind 的 dark: 变体一致。所以这给你实现了和 dark: 类似的机制,来根据父元素开启某些样式。Hope this helps! Let me know if you have any other questions. (edited)
这是 AI 给我的方案中距离正确答案最近的一次 ,但是仍旧无效,我又在这个问题的基础上尝试了十几轮的询问,得到的答案都是无效的。
自我救赎
在经历昨天下午两个小时外加今天上午两个小时的 AI 问询无果后,我悟了:就当从来没有 AI,早些时候我怎么解决问题现在还怎么解决,于是:
我在一些前端群里发求助信息,与人交流;
同时我开始下载 Tailwind CSS 源码开始审查源码看源码是如何实现 dark mode 的。
if (mode === false) { mode = 'media' log.warn('darkmode-false', [ 'The `darkMode` option in your Tailwind CSS configuration is set to `false`, which now behaves the same as `media`.', 'Change `darkMode` to `media` or remove it entirely.', 'https://tailwindcss.com/docs/upgrade-guide#remove-dark-mode-configuration', ]) }
Classes provide a means of bundling data and functionality together. Creating a new class creates a new type of object, allowing new instances of that type to be made. Each class instance can have attributes attached to it for maintaining its state. Class instances can also have methods (defined by its class) for modifying its state.
Return a new featureless object. object is a base for all classes. It has methods that are common to all instances of Python classes. This function does not accept any arguments. object does not have a __dict__, so you can’t assign arbitrary attributes to an instance of the object class.
#ifdef Py_TRACE_REFS /* Define pointers to support a doubly-linked list of all live heap objects. */ #define _PyObject_HEAD_EXTRA \ struct _object *_ob_next; \ struct _object *_ob_prev;
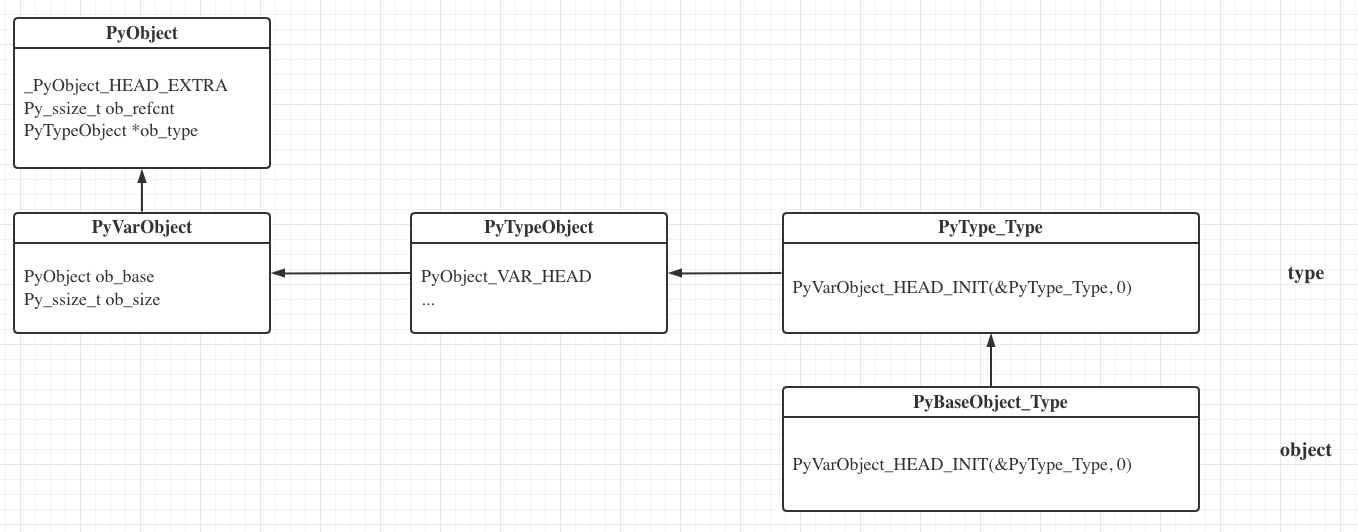
/* Nothing is actually declared to be a PyObject, but every pointer to * a Python object can be cast to a PyObject*. This is inheritance built * by hand. Similarly every pointer to a variable-size Python object can, * in addition, be cast to PyVarObject*. * * 实际上没有任何东西被声明为 PyObject, * 但是每一个指向 Python 对象的指针都可以被转换为 PyObject。 * 这是通过手动强制建立的继承关系。 * 同样地,每个指向可变大小的 Python 对象的指针都可以被转换为 PyVarObject */ typedefstruct _object { // 代表了两个 PyObject* 双向链表的指针,用于把堆上的所有对象链接起来, // 只会在开启了 Py_TRACE_REFS 宏的时候进行构造,方便调试; _PyObject_HEAD_EXTRA
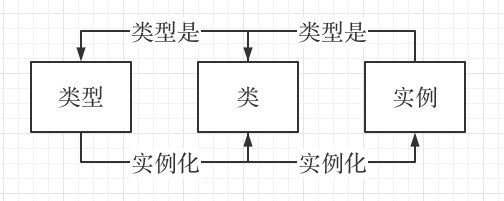
从 Python 官方文档来看,type 关键字和 object 关键字一样对应的是一个可调用对象,下面是官方文档对 type 的描述:
With one argument, return the type of an object. The return value is a type object and generally the same object as returned by object.class.
The isinstance() built-in function is recommended for testing the type of an object, because it takes subclasses into account.
With three arguments, return a new type object. This is essentially a dynamic form of the class statement. The name string is the class name and becomes the name attribute. The bases tuple contains the base classes and becomes the bases attribute; if empty, object, the ultimate base of all classes, is added. The dict dictionary contains attribute and method definitions for the class body; it may be copied or wrapped before becoming the dict attribute.
传入一个参数时,返回 object 的类型。 返回值是一个 type 对象,通常与 object.class 所返回的对象相同。
推荐使用 isinstance() 内置函数来检测对象的类型,因为它会考虑子类的情况。
传入三个参数时,返回一个新的 type 对象。 这在本质上是 class 语句的一种动态形式,name 字符串即类名并会成为 name 属性;bases 元组包含基类并会成为 bases 属性;如果为空则会添加所有类的终极基类 object。 dict 字典包含类主体的属性和方法定义;它在成为 dict 属性之前可能会被拷贝或包装。
/* PyTypeObject structure is defined in cpython/object.h. In Py_LIMITED_API, PyTypeObject is an opaque structure. */ typedefstruct _typeobjectPyTypeObject;
本文的主体内容大部分来自对 PEP 343 原文的翻译,其余部分为本人对原文的理解,在整理过程中我没有刻意地区分翻译的部分和我个人理解的部分,这两部分内容被糅杂在一起形成了本文。因此,请不要带着「本文的内容是百分之百正确」的想法阅读。如果文中的某些内容让你产生疑惑,你可以给我留言与我讨论或者对比 PEP 343 的原文加以确认。
摘要
本 PEP 为 Python 增加了一个新的语法:with,它能够更加简便的代替标准的 try/finally 语法。
在本 PEP 中,上下文管理器 提供了 __enter__() 和 __exit__() 方法,分别在进入和退出 with 语句时被调用。
mgr = (EXPR) exit = type(mgr).__exit__ # Not calling it yet value = type(mgr).__enter__(mgr) exc = True
try: try: VAR = value # Only if "as VAR" is present BLOCK except: # The exceptional case is handled here # 如果 BLCOK 部分出现异常 exc = False ifnot exit(mgr, *sys.exc_info()): raise # The exception is swallowed if exit() returns true # 如果 exit() 返回 true,则异常会被忽略 finally: # The normal and non-local goto case are handled here # 如果 BLOCK 没有异常或者执行了 non-local goto if exc: exit(mgr, None, None, None)
classGeneratorContextManager(object): def__init__(self, gen): self.gen = gen def__enter__(self): try: return self.gen.next() except StopIteration: raise RuntimeError("generator didn't yield") def__exit__(self, type, value, traceback): if type isNone: try: self.gen.next() except StopIteration: return else: raise RuntimeError("generator didn't stop") else: try: self.gen.throw(type, value, traceback) raise RuntimeError("generator didn't stop after throw()") except StopIteration: returnTrue except: # only re-raise if it's not the exception that was # passed to throw(), because __exit__() must not raise # an exception unless __exit__() itself failed. But # throw() has to raise the exception to signal # propagation, so thi fixes the impedance mismatch # between the throw() protocol and the __exit__() # protocol . # 只有当它不是传递给 throw() 的异常时才会重新被抛出, # 因为 __exit__() 只能在方法本身执行失败的时候抛出异常 # 但是 throw() 必须引发异常来传递信号 # 所以 thi 修复了 throw() 协议和 __exit__() 协议之间的不协调 if sys.exc_info()[1] isnot value: raise
@contextmanager defopening(filename): f = open(filename) # IOError is untouched by GeneratorContext try: yield f finally: f.close() # Ditto for errors here(howere unlikely)
with locked(myLock): # Code here executes with myLock held. The lock is # guaranteed to be released when the block is left (even # if via return or by an uncaught exception). # 这里的代码是在持有 myLock 的情况下被执行的。 # 这个锁被确保在离开 with 语句之后被释放,即使在执行过程中有中断或异常
opened:文件管理
在语句开始时通过特定模式打开文件,离开时关闭文件:
1 2 3 4 5 6 7
@contextmanager defopened(filename, mode="r"): f = open(filename, mode) try: yield f finally: f.close()
可以这样使用:
1 2 3
with opened("/etc/passwd") as f: for line in f: print line.rstrip()
defsin(x): # Return the sine of x as measured in radians. # 返回以弧度为单位的x的正弦。 with extra_precision(): i, lasts, s, fact, num, sign = 1, 0, x, 1, x, 1 while s != lasts: lasts = s i += 2 fact *= i * (i-1) num *= x * x sign *= -1 s += num / fact * sign # The "+s" rounds back to the original precision, # so this must be outside the with-statement: return +s
another decimal
一个简单的 decimal 模块的上下文管理器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
@contextmanager deflocalcontext(ctx=None): """Set a new local decimal context for the block""" # Default to using the current context if ctx isNone: ctx = getcontext() # We set the thread context to a copy of this context # to ensure that changes within the block are kept # local to the block. newctx = ctx.copy() oldctx = decimal.getcontext() decimal.setcontext(newctx) try: yield newctx finally: # Always restore the original context decimal.setcontext(oldctx)
使用案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from decimal import localcontext, ExtendedContext
defsin(x): with localcontext() as ctx: ctx.prec += 2 # Rest of sin calculation algorithm # uses a precision 2 greater than normal return +s # Convert result to normal precision
defsin(x): with localcontext(ExtendedContext): # Rest of sin calculation algorithm # uses the Extended Context from the # General Decimal Arithmetic Specification return +s # Convert result to normal context
@contextmanager defnested(*contexts): exits = [] vars = [] try: try: for context in contexts: exit = context.__exit__ enter = context.__enter__ vars.append(enter()) exits.append(exit) yield vars except: exc = sys.exc_info() else: exc = (None, None, None) finally: while exits: exit = exits.pop() try: exit(*exc) except: exc = sys.exc_info() else: exc = (None, None, None) if exc != (None, None, None): # sys.exc_info() may have been # changed by one of the exit methods # so provide explicit exception info raise exc[0], exc[1], exc[2]
使用案例
1 2
with nested(a, b, c) as (x, y, z): # Perform operation
等同于:
1 2 3 4
with a as x: with b as y: with c as z: # Perform operation
GEN_CREATED: Waiting to start execution. GEN_RUNNING: Currently being executed by the interpreter. GEN_SUSPENDED: Currently suspended at a yield expression. GEN_CLOSED: Execution has completed.
ASGI (Asynchronous Server Gateway Interface) is a spiritual successor to WSGI, intended to provide a standard interface between async-capable Python web servers, frameworks, and applications.
ASGI(异步服务器网关接口)是 WSGI 的精神续作,目的是为具有异步功能的 Python Web 服务器、框架和应用之间提供一个标准接口。
ASGI Server 应该负责处理所有入站和出站的分块传输编码。当一个带有 chunked encoded body 的请求通过 ASGI Server 时,它应该自动去掉请求的分块以 plain body bytes 的形式提供给 ASGI Application。当一个没有 Content-Length 的响应被提供给 ASGI Server 时,它可以按照合适的方式进行 chunked。
Request - receive event
由 ASGI Server 发送给 ASGI Application 以标识一个入站请求。关于这个请求的大部分信息都在对应的 Connection Scope 内。
Receive 中的 body message 是一种传输大量大的入站 HTTP body 块的方式,并且是判断何时执行「实际处理请求的代码」的触发器(因此不应该在仅有一个 Connection Scope 打开时就触发「实际处理请求的代码」)。
注意:如果请求发送时附带了 Transfer-Encoding: chunked 头,ASGI Server 需要负责处理这种编码。http.request message 应该只包含每个 chunk 的解码信息。
Request Receive Event Message 包含:
名称
类型
描述
type
Unicode String
“http.request”
body
Byte String
请求主体,默认为 b””,如果设置了 more_body = True,则将其视为 body chunk 链的一部分,并与后续的 chunks 进行关联
more_body
Bool
标志着是否还有额外的 body 内容,如果是 True 表示还有 body 内容,ASGI Application 需要等待,知道有一个为 False 的 chunk 到达
Response Start - send event
由 ASGI Application 发送给 ASGI Server,用于标识开始向 Web Client 发送响应。在此之后需要紧跟至少一个 response content message。ASGI Server 在接收到至少一个 Response Body 之前不得向 Web Client 发送响应。
ASGI Application 可能会在消息中发送一个 Transfer-Encoding header,但是 ASGI Server 必须忽略它。ASGI Server 需要自己处理 Transfer-Encoding,如果应用程序呈现的响应没有设置 Content-Length,可以选择使用 Transfer-Encoding: chunked。
asyncdefapp(scope, receive, send): if scope["type"] == "lifespan": whileTrue: message = await receive() if message["type"] == "lifespan.startup": # Do some startup here await send({"type": "lifespan.startup.complete"}) elif message["type"] == "lifespan.shutdown": # Do some shutdown here await send({"type": "lifespan.shutdown.complete"}) return else: # Handle other pass
Scope
Lifespan Scope 会持续存在直到事件循环结束。
Lifespan Scope Message 包含:
名称
类型
描述
type
Unicode String
“lifespan”
asgi[“version”]
Unicode String
ASGI 协议版本
asgi[“spec_version”]
Unicode String
子协议版本,默认 “1.0”
如果在调用带有 lifespan.startup 消息的 Application 或处理 type 是 lifespan 的 Scope 时抛出了异常,ASGI Server 需要继续执行但不 send any lifespan events。
算法成立的原因:再此方法中公开数据有 $p,g,Y_{A},Y_{B}$,若想要通过公开数据计算 $K$,则需要求取 $Y_{A} = g^{a} mod p \mid Y_{B} = g^{b} mod p$ 中的 a 或 b,求解此类问题一般使用穷举法,时间复杂度为 $O(p)$,只要 p 足够大就能够保证此方法目前可以达到计算机安全的要求。
# Traceback (most recent call last): # File "test.py", line 3, in <module> # class C(A, B): pass # TypeError: Cannot create a consistent method resolution # order (MRO) for bases A, B
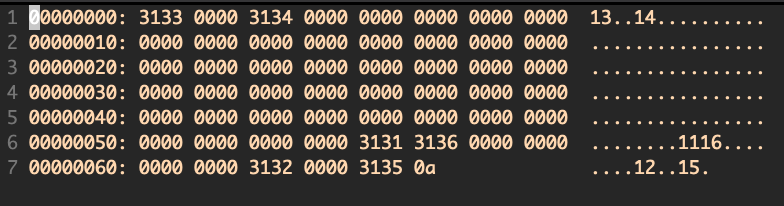
db '11' section test1 align=16 db '12' section test2 start=12 db '13' section test3 vstart=0x7c00 db '14' section test4 follows=test1 db '15' section .text start=100 db '16'
This document specifies a proposed standard interface between web servers and Python web applications or frameworks, to promote web application portability across a variety of web servers.
本文档详细描述了一个建议用在 Web 服务器和 Python Web 应用或框架之间的标准接口,以提升 Web 应用在各类 Web 服务器之间的可移植性。
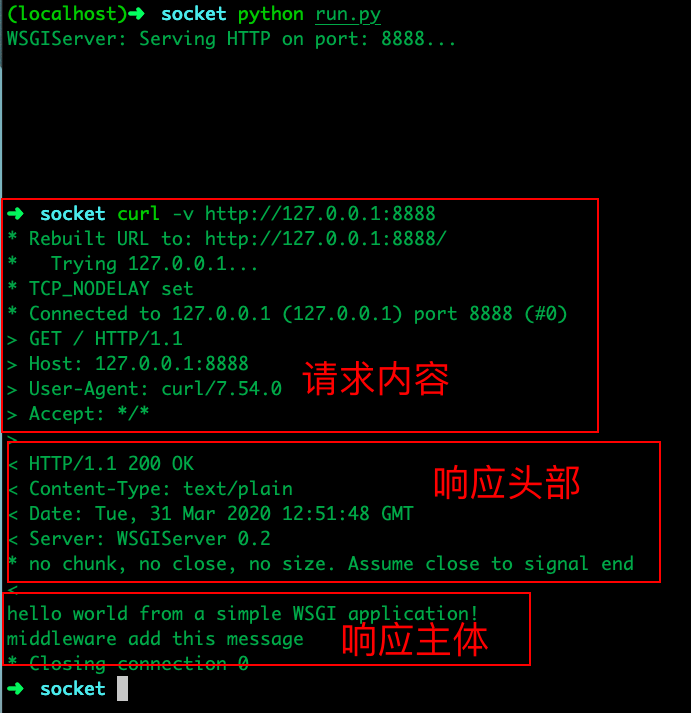
那 WSGI 到底解决了什么问题?这个在 PEP 3333 中有详细的解释,简单的说一下我的理解:在 WSGI 诞生之前,就已经存在了大量使用 Python 编写的 Web 应用框架,相应的也存在很多 Web 服务器。但是,各个 Python Web 框架和 Python Web 服务器之间不能互相兼容。夸张一点说,在当时如果想要开发一个 Web 框架说不定还得单独为这个框架开发一个 Web 服务器(而且这个服务器别的框架还不能用)。为了解决这一现象 Python 社区提交了 PEP 333,正式提出了 WSGI 这个概念。
简单的理解:只要是兼容 WSGI 的 Web 服务器和 Web 框架就能配套使用。开发服务器的程序员只需要考虑在兼容 WSGI 的情况下如何更好的提升服务器程序的性能;开发框架的程序员只需要考虑在兼容 WSGI 的情况下如何适应尽可能多业务开发逻辑(以上只是举例并非真的这样)。
WSGI 解放了 Web 开发者的精力让他们可以专注于自己需要关注的事情。
WSGI 做了什么事情?
注:为了简练而写成了 WSGI 做了什么事情,实际上 WSGI 只是一个规范并不是实际的代码,准确的来说应该是「符合 WSGI 规范的 Web 体系做了什么事情?」
上面已经提到,WSGI 通过规范化 Web 框架和 Web 服务器之间的接口,让兼容了 WSGI 的框架和服务器能够自由组合使用……
所以,WSGI 究竟做了什么,让一切变得如此简单?
在 PEP 3333 中对 WSGI 进行了一段简单的概述,这里我结合看过的 一篇博文 进行简单的概括:
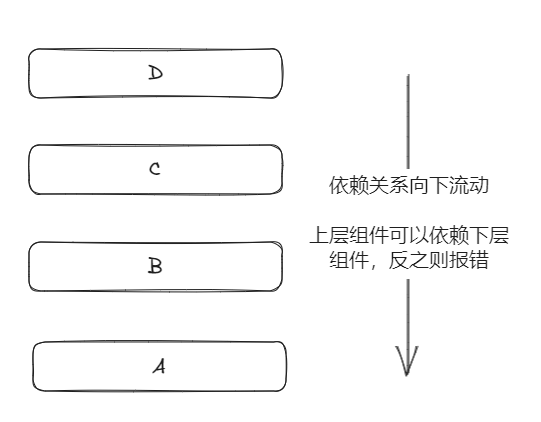
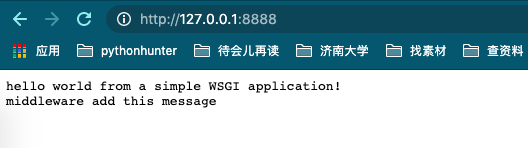
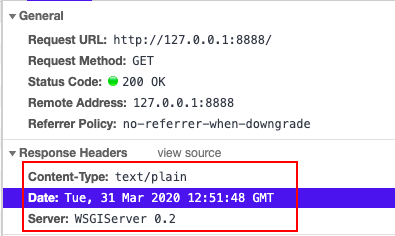
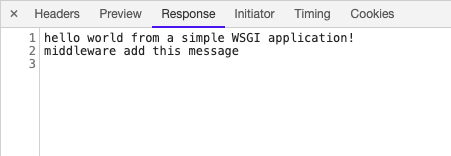
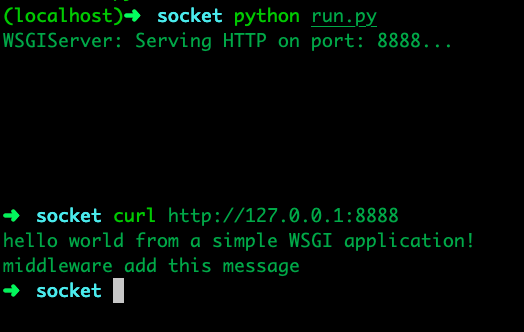
(简单来说)WSGI 将 Web 分成了三个部分,从上到下分别是:Application/Framework, Middleware 和 Server/Grageway,各个部分之间高度解耦尽可能的做到不互相依赖。
(通常情况下)客户端(一般为浏览器)会向 Server 发送 HTTP 请求以获取数据。
符合 WSGI 规范的 Server 在接收到请求之后会调用指定的符合 WSGI 规范的 Web Application,并传入 environ 和 start_response 两个参数(并不强制命名,只是一般会这么命名)。
Web Application 在接收到请求后会生成一个打包好的 HTTP Response 传给 start_response。
Server 会将 HTTP Response 进行汇总待请求处理完且没有错误时将整个 HTTP Response 内容返回给客户端。
Middleware 属于三个部分中最为特别的一个,对于 Server 他是一个 Application,对于 Application 它是一个 Server。通俗的来说就是 Middleware 面对 Server 时能够展现出 Application 应有的特性,而面对 Application 时能够展现出 Server 应有的特性,由于这一特点 Middleware 在整个协议中起到了承上启下的功能。在现实开发过程中,还可以通过嵌套 Middleware 以实现更强大的功能。
WSGI 是如何工作的?
通过上一小节能够大概的了解到 WSGI 在一次完整的请求中究竟做了什么。下面再来介绍一下一个完整的 WSGI Web 体系是如何工作的。